Homepage
Open in app
Sign in
Get started
Ipsos Synthesio Engineering
A fun yet professional team of engineers that works together to build a world class Social Listening platform
Follow
How we reclaimed 100 TB+ of storage with a single Elasticsearch API call
How we reclaimed 100 TB+ of storage with a single Elasticsearch API call
At Ipsos Synthesio, we use Elasticsearch to handle our massive amounts of data. It’s a big part of our tech setup, involving hundreds of…
Hugo Chargois
May 3
Our custom Conda-based Python build system
Our custom Conda-based Python build system
Combining the powers of conda, conda-pack and a custom self-extracting archive making tool
Hugo Chargois
Dec 5, 2022
Our first contribution to Elasticsearch
Our first contribution to Elasticsearch
At Synthesio, we’re heavy users of Elasticsearch, and we’re proud to have submitted our very first patch, that’s now included in v7.11
Hugo Chargois
Feb 18, 2021
Precision, Accuracy and F1 Score for Multi-Label Classification
Precision, Accuracy and F1 Score for Multi-Label Classification
Multi-Label Classification
Issa Memari
Jan 12, 2021
We are hiring! SRE, Frontend Engineers, Data Engineers, Data Science Engineers…
See our job offers
Latest
Assitan Koné
Dec 3, 2019
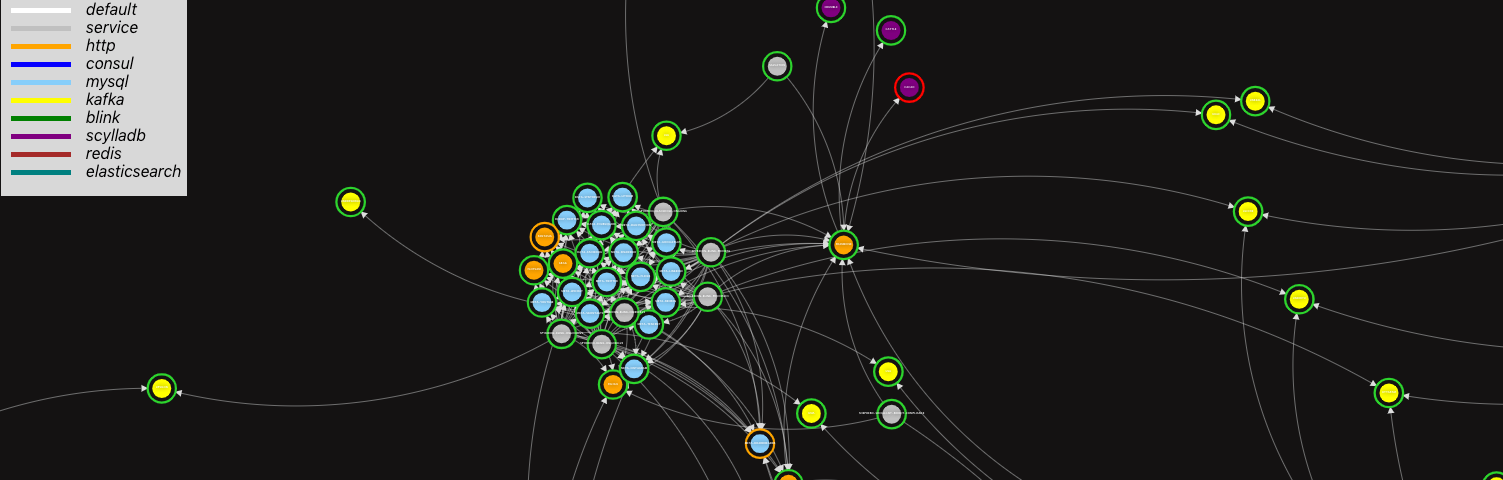
React + D3.js + Canvas: challenges for a visual representation of an infrastructure
Read more…
170
1 response
Issa Memari
Nov 26, 2019
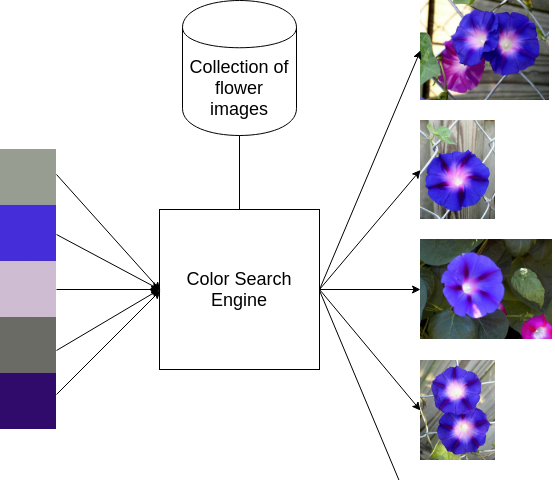
A journey towards creating a color search engine
Read more…
166
2 responses
Julien
Nov 12, 2019
Data science and the art of storytelling
When we look at data scientists job offers nowadays, this is hard to spot a common
…
Read more…
130
Data Science
Peaks and trends detection in time series for social data
Peaks and trends detection in time series for social data
Authors: Dimitri Trotignon
Dimitri Trotignon
Jan 8, 2019
Data Scientist vs Data Science Engineer
Data Scientist vs Data Science Engineer
Data Science jobs are many and varied nowadays. At Synthesio we felt the need to define a difference between Data Scientist and what we…
Julien
Sep 28, 2018
About Ipsos Synthesio Engineering
Latest Stories
Archive
About Medium
Terms
Privacy
Teams